

"Say when" for AI in music
How far can a song lean on AI before it becomes unlistenable?

If you haven’t checked out the test from last week, give that a go first.

picture that - original track (Version A)
On an overcast October afternoon, over Kona drafts and disappointing New York football, our collective gaze fell from the TVs to the table, to the phone in Alex’s hand.

What a way to enjoy retirement! A culturally relevant act by a nationally beloved figure. Everyone wants to be a DJ, even (especially) Obama.
I so badly wanted this to be real, but a pitch-black background for a DJing president would never be the case. Sadly, slop.
Our conversation shifted towards the slop we’re being fed by platforms originally meant to connect us.
How do you know when you’ve seen AI? What throws you off?
Alex (videographer/tri-linguist at Bloomberg) said something to the tune of an inconsistency in image clarity. Gordon (guitarist/producer/mRNA at Sanofi) echoed with “you know it when you see it.”
How about when you’ve heard AI?
A Bavarian pretzel and a puzzled silence arrived at the table. Alex and Gordon knew it was here, but hadn’t heard anything as obvious as what they’d seen. A collective shrug of shoulders signaled a non-resolution as we panned back to the Giants-Broncos game that had finally gotten interesting in the 4th quarter.
Beers finished, but questions loomed.
If our ears can’t reliably detect AI’s presence in music, what does that mean for trust in what we listen to?
And if a song attracts you but was shaped by a machine, does it matter, or does knowing its artificial influence change the value we assign to the music?
Is that music actually “slop”?
Perceived “slop” is as attitudinal as it is sensory. Several studies conducted across the arts conclude that adding an “AI-made” label depresses aesthetic ratings and authenticity, even when stimuli are otherwise indistinguishable. This is more obvious in the appearance of text and image, but it’s the same dance in music, where simply believing creative work is AI-generated can shift our evaluations of it. The point at which listeners say “this is too much AI” depends not only on sound but also on disclosure and expectation.
But music is tougher to decipher. Repeating what Gordon said: you know it when you see it with visual work. There, AI influence is more black-and-white; you observe a person move strangely, a blur of a logo, the em-dash we’ve become more sensitive to in writing. Once you see it, the work is written off as AI, and it has now been grouped as some inhuman “other”.
But with music, AI may have made its mark on composition, sound design, mixing, mastering, or performance.
And to make things harder, we are, at best, just okay at detecting synthetic audio. Our hearing is predictive and integrative; we group notes, tones, phrases, timbres over time. So rather than honing in on a single static instance, edits are smoothed out by our hearing systems. We effectively get in our own way. Classic results show listeners hear missing sounds when they’re masked and perceive interrupted tones or textures as continuous. If there’s an unnatural hiccup in a track, we’ll definitely notice it, but then it’s gone by the next few bars.
This mostly explains why small manipulations are easy for us to miss, and why AI influence on music exists on a more slippery spectrum than visual media.
Experiment 01: Setting the Stage
With Suno’s cover/remix feature, I took my original track and ran it through their audio engine, controlling the effect of AI-influence using the parameters provided. To bypass major stylistic influence, I was able to put a period in the lyrics section, which satisfied the program requirements for remixing (they’ve since fixed this).
I worked within the Advanced Options dropdown, where the sliders allowed adjustment to the level of influence of Suno’s model on my original track.
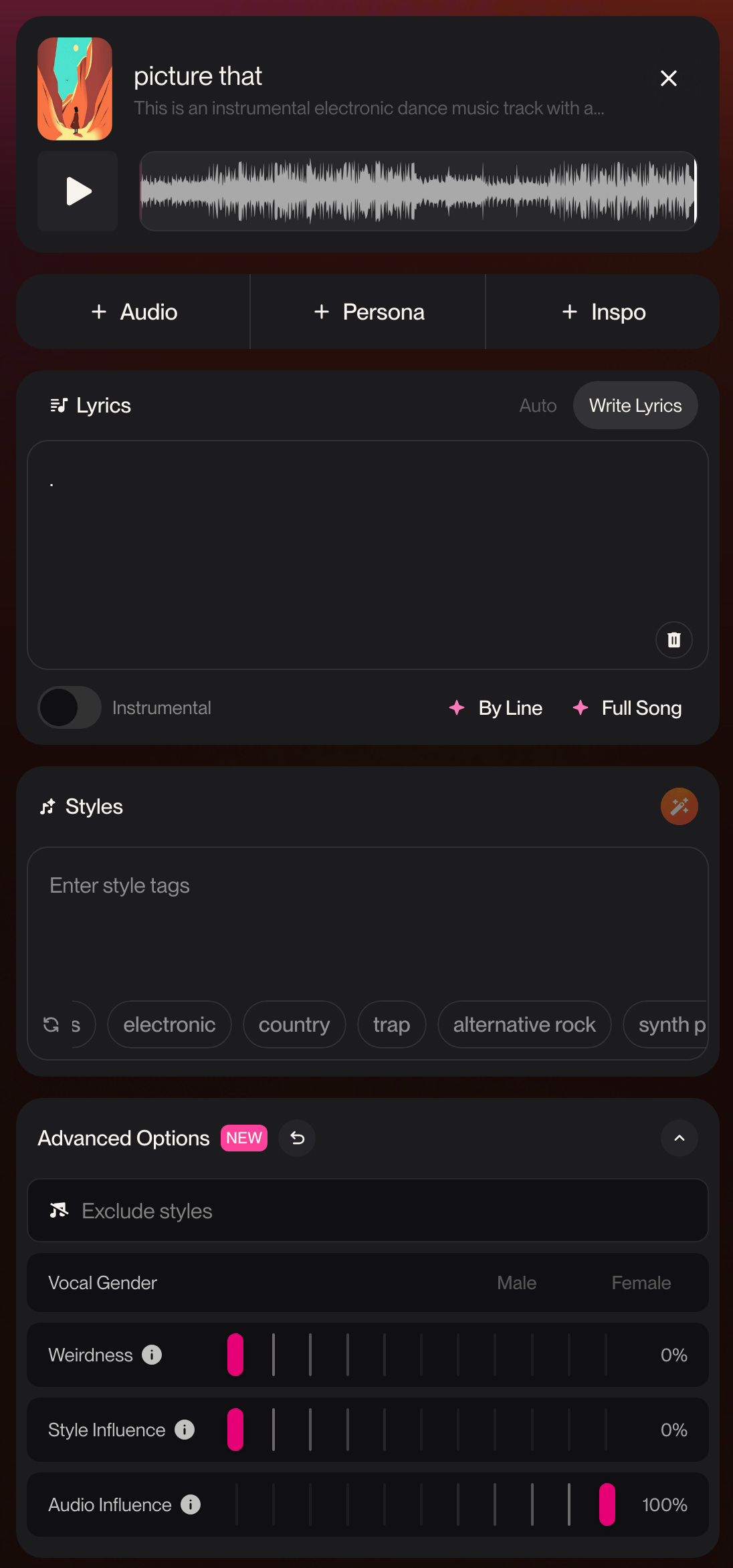
Weirdness: encourages less typical generations
Style Influence: how strongly the model enforces tagged style genres (bypassed this)
Audio Influence: how closely the output aligns with the sound of my original audio.
In the UI, higher = closer to original (0,0,100 ≈ minimal model sway)
With weirdness and style influence at 0 and audio influence at 100, Suno’s output should wholly maintain the sonic character and qualities of my original track.
This generated Version B in the experiment. All versions are below again for reference.
Version A (baseline) - my work
Version B (0 0 100) - as little model influence as parameters allow
Version C (0 0 50) - half-deviated from the baseline mix
Version D (75 0 100) - minimal deviation, but weirdness introduction (quarter)
Version E (50 0 50) - half-deviation from baseline + half weirdness
Version F (75 0 25) - mostly-deviated from baseline + quarter weirdness
To follow along as I run more experiments around our listening, feel free to…
Results
% of participants who chose X version as the one that “felt off”
B - 14%
C - 7%
D - 29%
E - 43%
F - 7%
For those who said no version got bad enough, here’s a bonus:
Version G (100 0 0) - good luck
This one was a treat; we’d made a full circle return to the shittiest of AM radio. Suno had 0% original audio influence, 0% style restraint, and 100% weirdness ability, and it spat out something that ultimately feels representative of what this thing is — an inhuman overstuffing of discernible sonic content.
Are we fucked?
This past September, researchers at the Federal University of Minas Gerais published a study that should make everyone pause. They ran a blind listening test with over 650 participants, asking them to distinguish between human-made and AI-generated songs from Suno, the same tool I used for this experiment.
They found that when song pairs were randomly selected (shuffle, radio, etc.), listeners performed no better than random guessing. They literally could not tell the difference.
Only when researchers deliberately paired highly similar songs (like this experiment) did listeners manage to identify AI music at rates any better than chance. Even then, their success heavily depended on identifying vocal cues and technical artifacts, otherwise known as the very elements that improve with each model update.
Their chilling conclusion: AI-generated music has reached perceptual parity with professional human compositions.
The gap hasn’t just narrowed. For random sequences of songs, the way you actually encounter music in the real world, the gap has closed.
What does this mean for us?
Several listeners noted in the test which ones sounded off, AND the ones they really liked. Versions C, D, and F got love, even over the original work.
This raised a few key questions:
Does knowing AI touched this track feel like I cheated you, or like I used a helpful tool? What’s the difference? Using Suno did feel like cutting corners and giving away creative agency, but quite a few listeners preferred AI-influenced versions, so…
If AI can generate versions of my work that some of you prefer, at what point am I just a prompt engineer for my own music? When does an “artist using AI” become an “AI using artist as source material”? Version E was 50% original audio, 50% algorithmic reinterpretation. Which half did the work?
But maybe I’m overthinking. Maybe the disclosure paradox cuts both ways, and maybe you don’t need to know. If the version you liked best was 75% AI-influenced, is it still my song? Is it still yours to connect with? Or does it belong to something in between, becoming a collaboration you never really consented to?
There’s another possibility I can’t ignore, which is that none of this matters if the music sounds good and moves you. That artistic authenticity is a luxury concern, and engagement is the only metric that counts. That I’m stressing over lines that listeners don’t care about drawing in the first place.
I don’t know which of these positions I believe, but I do know the question isn’t hypothetical anymore. It’s playing in your headphones right now, and you can’t unhear what you just learned about it.
Truth be told, I’ve been using AI-adjacent tools for as long as I’ve been producing. Pitch correction, timing quantization, chord generation, and algorithmic mastering have been in my toolkit since college, and I’m certainly not alone in leaning on these. The line between “production tool” and “gen AI” isn’t as clear as I led on when I first tapped Suno to build this test. What makes me comfortable with Auto-Tune but uncomfortable with Suno generating alternatives to my own mix? I’m not sure I have a good answer yet.
Which finally brings me to what I’m really sitting with: if the tools blur, if the listeners can’t tell, if you prefer the AI versions - Who gets to call themselves a musician anymore? And more importantly - do you care? That’s a question I’ll address soon. But for now, consider this:
Think about the last song you added to your library that really caught your ear. Would it matter to you if you found out?
Thanks for reading
Elias
What I’ve been listening to
Five jazz musicians fucking around for 15 minutes, you will find your moments of awe in human musical ability here.
An introspective, musically-entwined interview with a wrongfully-convicted man currently sitting on death row. Keith maintains his innocence and campaigns against the death penalty from behind bars. He picks out musical selections that have given him solace throughout his continued three-decade incarceration.
For more about Keith and his campaign, visit www.keithlamar.org

Absolute wizard with a trove of 2-3 hour mixes that make Excel feel like you’re in the matrix. Always a good pairing with the minutiae of d r i v i n g c o r p o r a t e s u c c e s s.
Thanks for writing this, it clarifies a lot. So curious how our brains percieve audio AI differntly!